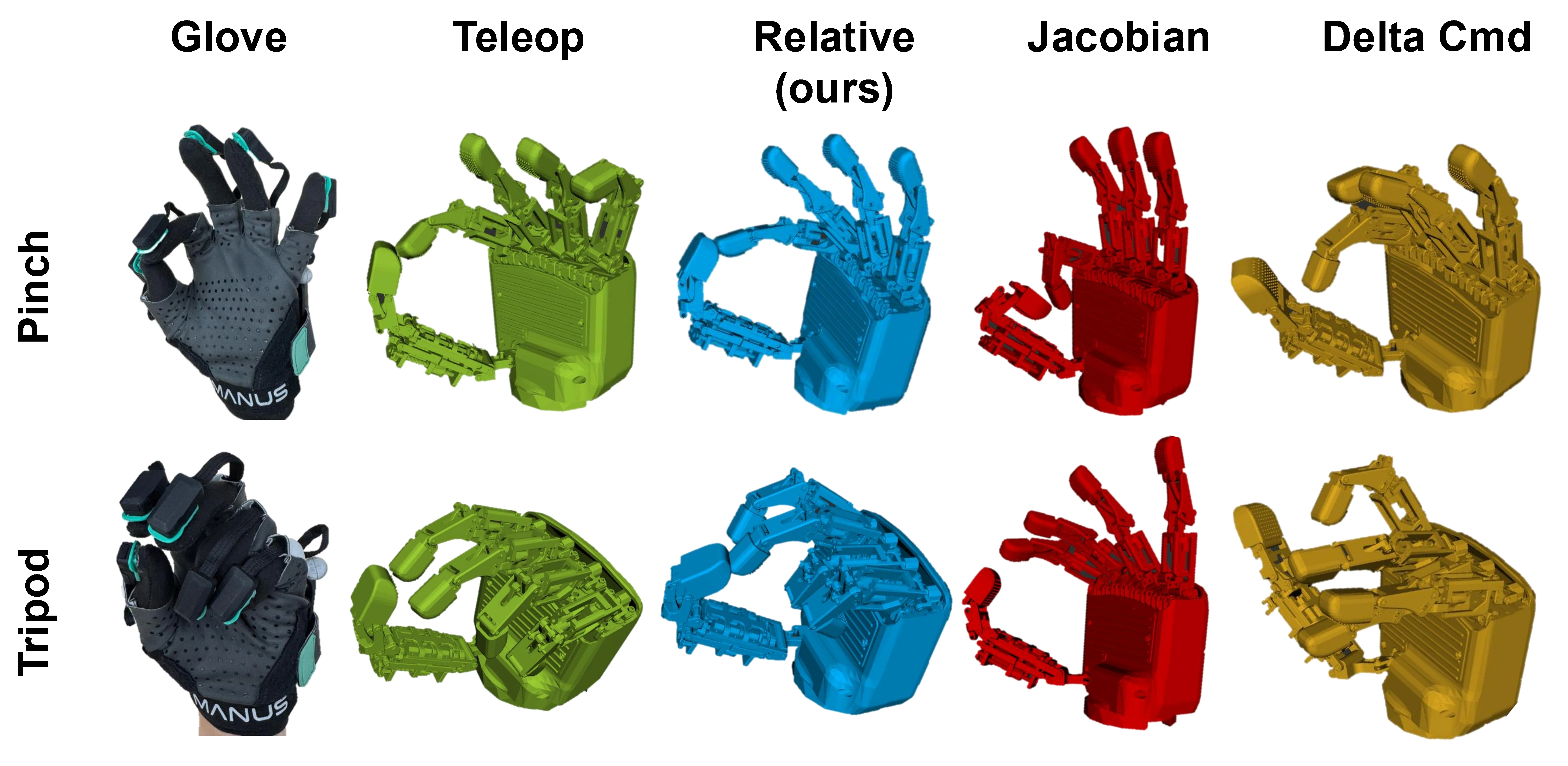
Abstract
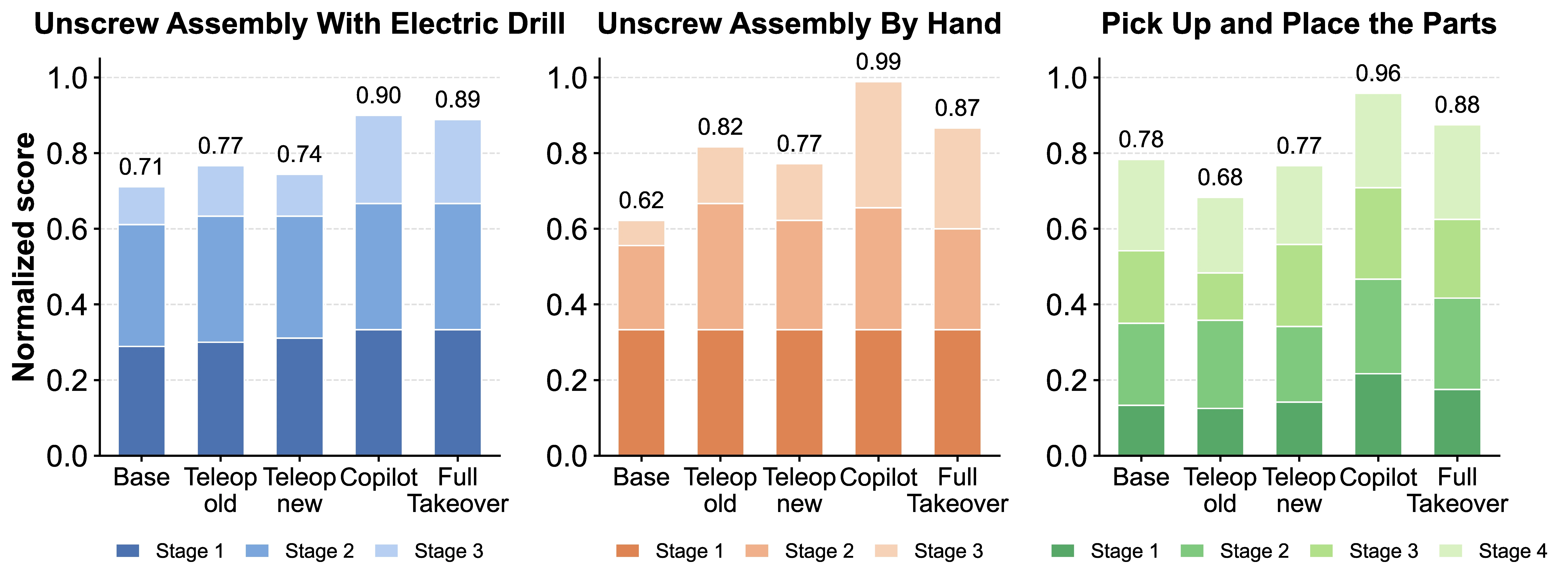
Vision-Language-Action (VLA) models are prone to compounding errors in dexterous manipulation, where high-dimensional action spaces and contact-rich dynamics amplify small policy deviations over long horizons. While Interactive Imitation Learning (IIL) can refine policies through human correction data, applying it to high-degree-of-freedom (DoF) robotic hands remains challenging due to a command mismatch between human teleoperation and policy execution at the intervention moment, which causes abrupt robot-hand configuration changes, or “gesture jumps”. We present Hand-in-the-Loop (HandITL), a seamless human-in-the-loop intervention method that blends human corrective intent with autonomous policy execution to avoid gesture jumps during bimanual dexterous manipulation. Compared with taking over control using direct teleoperation, HandITL reduces intervention jitter by 99.8% and preserves robust post-intervention manipulation, reducing grasp failures by 87.5% and mean completion time by 19.1%. We validate HandITL on tasks requiring bimanual coordination, tool use, and fine-grained long-horizon manipulation. When used to collect correction data for policy refinement, HandITL yields policies that outperform those trained with standard teleoperation data by 19% on average across three long-horizon dexterous tasks.